五、嵌入单词和类型
本文标题:Natural-Language-Processing-with-PyTorch(五)
文章作者:Yif Du
发布时间:2018 年 12 月 21 日 - 12:12
最后更新:2018 年 12 月 28 日 - 11:12
原始链接:http://yifdu.github.io/2018/12/21/Natural-Language-Processing-with-PyTorch(五)/
许可协议:署名-非商业性使用-禁止演绎 4.0 国际 转载请保留原文链接及作者。
在实现自然语言处理(NLP)任务时,我们需要处理不同类型的离散类型。最明显的例子是单词。单词来自一个有限的集合(也就是词汇表)。其他离散类型的示例包括字符、部分语言标记、命名实体、命名实体类型、解析特性、产品目录中的项等等。本质上,当任何输入特征来自有限(或可数无限)集时,它都是离散类型。
将离散类型(如单词)表示为密集向量是 NLP 中深度学习成功的核心。术语“表示学习”和“嵌入”是指学习从一种离散类型到向量空间中的一点的映射。当离散类型为词时,密集向量表示称为词嵌入(word embedding)。我们在第 2 章中看到了基于计数的嵌入方法的例子,比如词频-逆文档频率(TF-IDF)。在本章中,我们主要研究基于学习或基于预测(Baroni et al., 2014)的嵌入方法,即通过最大化特定学习任务的目标来学习表征;例如,根据上下文预测一个单词。基于学习的嵌入方法由于其广泛的适用性和性能而在法理上受到限制。事实上,单词嵌入在 NLP 任务中的普遍性为它们赢得了“NLP 的 Sriracha”的称号,因为您可以在任何 NLP 任务中使用单词嵌入,并期望任务的性能得到改进。但是我们认为这种绰号是误导的,因为与 Sriracha 不同,嵌入(embeddings)通常不是作为事后添加到模型中的,而是模型本身的基本组成部分。
在这一章中,我们讨论与嵌入词相关的向量表示:嵌入词的方法,优化嵌入词的方法,用于监督和非监督语言任务,可视化嵌入词的方法,以及组合嵌入词的句子和文件的方法。但是,您必须记住,我们在这里描述的方法适用于任何离散类型。
为什么要学习嵌入?
在前几章中,您看到了创建单词向量表示的传统方法。具体来说,您了解到可以使用单热表示—与词汇表大小相同的长度的向量,除了单个位置以外,其他地方都是 0,值为 1 表示特定的单词。此外,您还看到了计数表示——向量的长度与模型中唯一单词的数量相同,但是在向量中与句子中单词的频率相对应的位置上有计数。基于计数的表示也称为分布表示,因为它们的重要内容或意义是由向量中的多个维度表示的。分布表示具有悠久的历史(Firth, 1935),可以很好地用于许多机器学习和神经网络模型。这些表示,不是从数据中学习的,而是启发式构建的。
分布式表示的名称来源于这样一个事实:由于单词现在由低得多的密集向量表示(比如d = 100,而不是整个词汇的大小,可以是大约 105 到 106 或更高), 并且一个单词的含义和其他属性分布在这个密集向量的不同维度上。
低维的学习密集表示比我们在前几章中看到的基于单热和计数的向量有几个优点。首先,降低维度是计算效率。其次,基于计数的表示导致高维向量在多个维度上冗余地编码相似的信息,并且不共享统计强度。第三,输入中维数过高会导致机器学习和优化中的实际问题,这通常被称为“维数灾难”。“传统上,为了处理这个维度问题,我们使用了像 PCA/SVD 这样的降维方法,但有点讽刺的是,当维度以百万的顺序排列时(典型的 NLP 情况),这些方法不能很好地进行缩放。”第四,从特定于任务的数据中学习(或微调)的表示形式最适合手头的任务。使用 TF-IDF 等启发式方法或 SVD 等低维方法,不清楚嵌入方法的优化目标是否与任务相关。
嵌入的有效性
为了理解嵌入是如何工作的,让我们看一个用单热向量乘以线性层中的权重矩阵的例子,如图 5-1 所示。在第 3 章和第 4 章中,单热向量的大小与词汇表相同。这个向量被称为“单热”,因为它在索引中有一个 1,表示存在一个特定的单词。
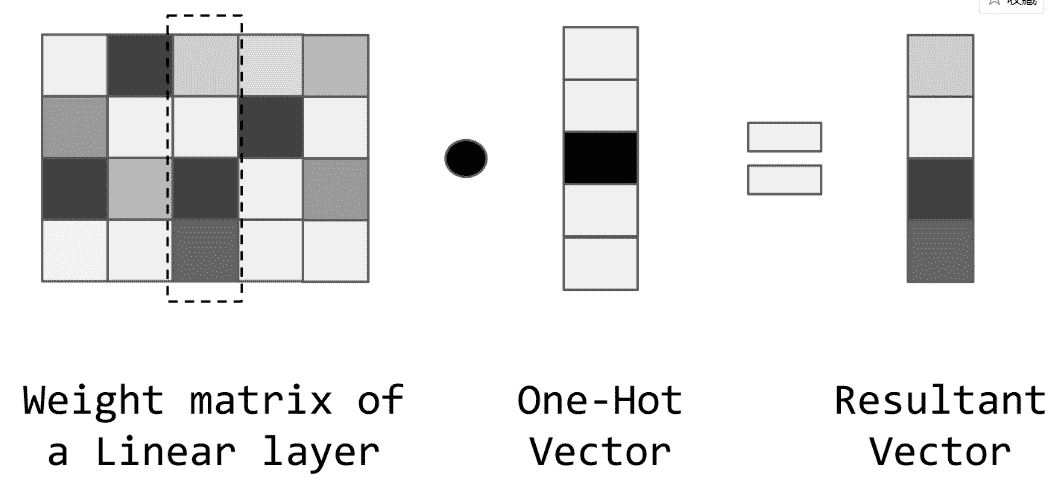
根据定义,接受这个单热向量作为输入的线性层的权值矩阵必须与这个单热向量的大小具有相同的行数。当您执行矩阵乘法时,如图 5-1 所示,结果向量实际上只是选择了由非零项指示的行。从这个观察结果中,我们可以跳过乘法步骤,直接使用整数作为检索所选行的索引。
关于嵌入效率的最后一点注意事项是,尽管图 5-1 中的示例显示的权重矩阵与传入的单热向量具有相同的维度,但情况并非总是如此。实际上,嵌入通常用于在低维空间中表示单词,而不是使用一个单热向量或基于计数的表示。在研究文献中,嵌入的典型尺寸从 25 维到 500 维不等,准确的选择可以归结为您必须节省的图形处理器单元(GPU)内存。
学习单词嵌入的方式
本章的目标不是教授特定的单词嵌入技术,而是理解什么是嵌入,如何以及在哪里使用它们,如何在模型中可靠地使用它们,以及理解它们的局限性。我们之所以这样做,是因为实践者很少发现自己处于需要编写嵌入训练算法的新单词的情况下。然而,在这一节中,我们将简要概述当前训练单词嵌入的方法。所有的单词嵌入方法都是用单词来训练的。但是是以一种监督的方式。这可以通过构造辅助监督任务来实现,在这些任务中,数据被隐式地标记,直观地认为,优化后用于解决辅助任务的表示形式将捕获文本语料库的许多统计和语言属性,以便普遍使用。以下是一些辅助任务的例子:
- 给出一个单词序列,预测下一个单词。这也称为语言建模任务。
- 给定单词前后的顺序,预测缺失的单词。
- 给定一个单词,预测出现在窗口中的单词,独立于位置。
当然,这个列表是不完整的,辅助任务的选择取决于算法设计者的直觉和计算费用。例如 Glove、连续词袋、Skipgrams 等等。我们参考 Goldberg, 2017,第 10 章,但我们将简要研究 CBOW 模型。但是,对于大多数目的来说,使用预先训练好的单词嵌入并对它们进行微调就足够了。
预训练词嵌入的实践用法
本章的大部分内容,以及本书的后面部分,都涉及到使用经过预先训练的单词嵌入。使用前面描述的许多方法中的一种,可以免费下载和使用预先训练过的单词嵌入、在大型语料(类似于所有新闻、维基百科和通用爬行器)上进行训练的单词嵌入。本章的其余部分将展示如何有效地加载和查找这些嵌入,研究词嵌入的一些属性,并展示在 NLP 任务中使用预先训练的嵌入的示例。
加载嵌入
词嵌入已经变得非常流行和普及,您可以从原始的 Word2Vec、Stanford 的 GLoVE、Facebook 的 FastText 和许多其他版本下载许多不同的版本。通常,嵌入将以以下格式出现:每行以嵌入的单词/类型开始,然后是一系列数字(即,向量表示)。这个序列的长度就是表示的维数(也就是嵌入维数)。嵌入维数通常是数百。标记(token)类型的数量通常是词汇表的大小,以百万计。例如,这里是来自 GloVe 的狗和猫向量的前七个维度: dog: -1.242 -0.360 0.573 0.367 0.600 -0.189 1.273 … cat: -0.964 -0.610 0.674 0.351 0.413 -0.212 1.380 …
为了有效地加载和处理嵌入,我们描述了一个实用工具类,即预训练。该类在内存中构建所有单词向量的索引,以方便使用近似的最近邻包进行快速查找和最近邻查询。这个类显示在示例 5-1 中的第一个输入中。
示例 5-1:使用预训练词嵌入
Input[0]
import numpy as np
from annoy import AnnoyIndex
class PreTrainedEmbeddings(object):
def __init__(self, word_to_index, word_vectors):
"""
Args:
word_to_index (dict): mapping from word to integers
word_vectors (list of numpy arrays)
"""
self.word_to_index = word_to_index
self.word_vectors = word_vectors
self.index_to_word = \
{v: k for k, v in self.word_to_index.items()}
self.index = AnnoyIndex(len(word_vectors[0]),
metric='euclidean')
for _, i in self.word_to_index.items():
self.index.add_item(i, self.word_vectors[i])
self.index.build(50)
@classmethod
def from_embeddings_file(cls, embedding_file):
"""Instantiate from pre-trained vector file.
Vector file should be of the format:
word0 x0_0 x0_1 x0_2 x0_3 ... x0_N
word1 x1_0 x1_1 x1_2 x1_3 ... x1_N
Args:
embedding_file (str): location of the file
Returns:
instance of PretrainedEmbeddings
"""
word_to_index = {}
word_vectors = []
with open(embedding_file) as fp:
for line in fp.readlines():
line = line.split(" ")
word = line[0]
vec = np.array([float(x) for x in line[1:]])
word_to_index[word] = len(word_to_index)
word_vectors.append(vec)
return cls(word_to_index, word_vectors)
Input[1]
embeddings = \
PreTrainedEmbeddings.from_embeddings_file('glove.6B.100d.txt')
在这些例子中,我们使用 Glove 词嵌入。下载它们之后,可以使用PretrainedEmbeddings类进行实例化,如示例 5-1 中的第二个输入所示。
词嵌入之间的关系
词嵌入的核心特征是对句法和语义关系进行编码,这些句法和语义关系表现为词的使用规律。例如,人们谈论猫和狗的方式非常相似(讨论宠物、喂食等)。因此,它们的嵌入彼此之间的距离比它们与其他动物(如鸭子和大象)的距离要近得多。 我们可以从几个方面探讨嵌入词编码的语义关系。最流行的一种方法是类比任务(SAT 等考试中常见的推理任务): Word1 : Word2 :: Word3 : __
在这个任务中,你被提供了前三个单词,需要确定第四个单词与前两个单词之间的关系是一致的。使用嵌入词,我们可以对其进行空间编码。首先,我们从单词 1 中减去单词 2。这个差异向量编码了Word1和Word2之间的关系。然后可以将这个差异添加到Word3中,从而生成一个接近第四个单词的向量,即空白符号所在的位置。使用这个结果向量对索引执行最近邻查询可以解决类比问题。计算这个的函数,如例 5-2 所示,完成了刚刚描述的工作:使用向量算法和近似的最近邻索引,完成类比。
示例 5-2:使用词嵌入的类比任务
Input[0]
import numpy as np
from annoy import AnnoyIndex
class PreTrainedEmbeddings(object):
""" implementation continued from previous code box"""
def get_embedding(self, word):
"""
Args:
word (str)
Returns
an embedding (numpy.ndarray)
"""
return self.word_vectors[self.word_to_index[word]]
def get_closest_to_vector(self, vector, n=1):
"""Given a vector, return its n nearest neighbors
Args:
vector (np.ndarray): should match the size of the vectors
in the Annoy index
n (int): the number of neighbors to return
Returns:
[str, str, ...]: words nearest to the given vector.
The words are not ordered by distance
"""
nn_indices = self.index.get_nns_by_vector(vector, n)
return [self.index_to_word[neighbor]
for neighbor in nn_indices]
def compute_and_print_analogy(self, word1, word2, word3):
"""Prints the solutions to analogies using word embeddings
Analogies are word1 is to word2 as word3 is to __
This method will print: word1 : word2 :: word3 : word4
Args:
word1 (str)
word2 (str)
word3 (str)
"""
vec1 = self.get_embedding(word1)
vec2 = self.get_embedding(word2)
vec3 = self.get_embedding(word3)
# Simple hypothesis: Analogy is a spatial relationship
spatial_relationship = vec2 - vec1
vec4 = vec3 + spatial_relationship
closest_words = self.get_closest_to_vector(vec4, n=4)
existing_words = set([word1, word2, word3])
closest_words = [word for word in closest_words
if word not in existing_words]
if len(closest_words) == 0:
print("Could not find nearest neighbors for the vector!")
return
for word4 in closest_words:
print("{} : {} :: {} : {}".format(word1, word2, word3,
word4))
有趣的是,简单的单词类比任务可以证明单词嵌入捕获了各种语义和语法关系,如示例 5-3 所示。
示例 5-3:一组语言关系以向量类比编码
Input[0]
# Relationship 1: the relationship between gendered nouns and pronouns
embeddings.compute_and_print_analogy('man', 'he', 'woman')
Output[0]
man : he :: woman : she
Input[1]
# Relationship 2: Verb-Noun relationships
embeddings.compute_and_print_analogy('fly', 'plane', 'sail')
Output[1]
fly : plane :: sail : ship
Input[2]
# Relationship 3: Noun-Noun relationships
embeddings.compute_and_print_analogy('cat', 'kitten', 'dog')
Output[2]
cat : kitten :: dog : puppy
Input[3]
# Relationship 4: Hypernymy (broader category)
embeddings.compute_and_print_analogy('blue', 'color', 'dog')
Output[3]
blue : color :: dog : animal
Input[4]
# Relationship 5: Meronymy (part-to-whole)
embeddings.compute_and_print_analogy('toe', 'foot', 'finger')
Output[4]
toe : foot :: finger : hand
Input[5]
# Relationship 6: Troponymy (difference in manner)
embeddings.compute_and_print_analogy('talk', 'communicate', 'read')
Output[5]
talk : communicate :: read : interpret
Input[6]
# Relationship 7: Metonymy (convention / figures of speech)
embeddings.compute_and_print_analogy('blue', 'democrat', 'red')
Output[6]
blue : democrat :: red : republican
Input[7]
# Relationship 8: Adjectival Scales
embeddings.compute_and_print_analogy('fast', 'fastest', 'young')
Output[7]
fast : fastest :: young : youngest
虽然这种关系似乎是系统的语言功能,事情可能变得棘手。如例 5-4 所示,由于单词向量只是基于共现,关系可能是错误的。
示例 5-4:类比可能在简单的规模上失败
Input[0]
embeddings.compute_and_print_analogy('fast', 'fastest', 'small')
Output[0]
fast : fastest :: small : largest
示例 5-5 说明了最常见的类比对之一是如何编码带有性别的角色。
示例 5-5:在向量类比中编码的性别
Input[0]
embeddings.compute_and_print_analogy('man', 'king', 'woman')
Output[0]
man : king :: woman : queen
事实证明,区分语言规则和文化偏见是困难的。例如,医生并不是事实上的男性,护士也不是事实上的女性,但是这些长期存在于文化中的偏见被观察到作为语言的规律性,并被编入vector这个词中,如例 5-6 所示。
示例 5-6:编码在向量类比中的文化性别偏见
Input[0]
embeddings.compute_and_print_analogy('man', 'doctor', 'woman')
Output[0]
man : doctor :: woman : nurse
考虑到嵌入在 NLP 应用程序中的流行程度和使用正在上升,您需要注意嵌入中的偏差。去偏现有词嵌入在一个新的和令人兴奋的研究领域(Bolukbasi et al., 2016)。此外,我们建议您访问 ethicsinnlp.org,以获取伦理与 NLP 交叉的最新结果。
示例:学习单词嵌入的连续词袋
在本例中,我们将介绍构建和学习通用嵌入词的最著名模型之一,即 Word2Vec 连续词包(CBOW)模型。在本节中,当我们提到“CBOW 任务”或“CBOW 分类任务”时,隐含的意思是我们构建分类任务的目的是为了学习 CBOW 嵌入。CBOW 模型是一种多类分类任务,其表现为对单词文本进行扫描,创建单词的上下文窗口,从上下文窗口中删除中心单词,并将上下文窗口分类为丢失的单词。直觉上,你可以把它想象成一个填空任务。有一个句子缺了一个词,模特的工作就是找出那个词应该是什么。
这个例子的目的是介绍nn.Embedding层,封装嵌入矩阵(embedding matrix)的 PyTorch 模块。利用嵌入层,我们可以将标记的整数 ID 映射到用于神经网络计算的向量上。当优化器更新模型权重以最小化损失时,它还更新向量的值。通过这个过程,模型将学习如何以最有效的方式嵌入单词。
在本例的其余部分中,我们遵循标准的示例格式。在第一部分,我们介绍数据集,玛丽·雪莱(Mary Shelley)的小说《弗兰肯斯坦》。然后,我们讨论了从标记到向量化小批量的向量化流水线。然后,我们概述了 CBOW 分类模型以及如何使用嵌入层。接下来,我们将介绍训练程序;尽管如此,如果你已经连续阅读了这本书,在这一点上训练应该是相当常规的。最后,我们讨论了模型评估、模型推理以及如何检查模型。
《弗兰肯斯坦》数据集
在本例中,我们将从玛丽·雪莱(Mary Shelley)的小说《弗兰肯斯坦》(Frankenstein)的数字化版本构建一个文本数据集,可以通过古登堡计划(Project Gutenberg)获得。本节介绍预处理过程,为这个文本数据集构建一个 PyTorch 数据集类,最后将数据集分解为训练、验证和测试集。
从古腾堡项目分发的原始文本文件开始,预处理是最小的:我们使用 NLTK 的 Punkt 标记器将文本分割成不同的句子。然后,将每个句子转换为小写字母,并完全去掉标点符号。这种预处理允许我们稍后在空白中拆分字符串,以便检索标记列表。这一预处理功能是从“示例:餐厅评论情绪分类”中重用的。

下一步是将数据集枚举为一系列窗口,以便对 CBOW 模型进行优化。为此,我们迭代每个句子中的标记列表,并将它们分组到指定窗口大小的窗口中,如图 5-2 所示。
构建数据集的最后一步是将数据分割为三个集:训练集、验证集和测试集。回想一下,训练和验证集是在模型训练期间使用的:训练集用于更新参数,验证集用于度量模型的性能。测试集最多使用一次,以提供偏差较小的测量。在本例中(以及本书中的大多数示例中),我们使用了 70% 的训练集、15% 的验证集和 15% 的测试集。
窗口和目标的结果数据集装载了一个 panda DataFrame,并在CBOWDataset类中建立了索引。示例 5-7 展示了__getitem__代码片段,该代码片段利用向量化器将上下文(左右窗口)转换为向量。目标——窗口中心的单词——使用词汇表转换为整数。
示例 5-7:构造数据集类用于 CBOW 任务
class CBOWDataset(Dataset):
# ... existing implementation from Section 3.5
@classmethod
def load_dataset_and_make_vectorizer(cls, cbow_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
cbow_csv (str): location of the dataset
Returns:
an instance of CBOWDataset
"""
cbow_df = pd.read_csv(cbow_csv)
train_cbow_df = cbow_df[cbow_df.split=='train']
return cls(cbow_df, CBOWVectorizer.from_dataframe(train_cbow_df))
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dict with features (x_data) and label (y_target)
"""
row = self._target_df.iloc[index]
context_vector = \
self._vectorizer.vectorize(row.context, self._max_seq_length)
target_index = self._vectorizer.cbow_vocab.lookup_token(row.target)
return {'x_data': context_vector,
'y_target': target_index}
Vocabulary,Vectorizer和DataLoader
在 CBOW 分类任务中,从文本到向量化的迷你批量的管道大部分都是标准的:词汇表和DataLoader功能都与“示例:餐厅评论分类情感”中的示例完全一样。然而,与我们在第 3 章和第 4 章中看到的向量化器不同,向量化器不构造单热向量。相反,构造并返回一个表示上下文索引的整数向量。示例 5-8 给出了向量化函数的代码。
示例 5-8:用于 CBOW 数据的向量化器
class CBOWVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def vectorize(self, context, vector_length=-1):
"""
Args:
context (str): the string of words separated by a space
vector_length (int): an argument for forcing the length of index vector
"""
indices = \
[self.cbow_vocab.lookup_token(token) for token in context.split(' ')]
if vector_length < 0:
vector_length = len(indices)
out_vector = np.zeros(vector_length, dtype=np.int64)
out_vector[:len(indices)] = indices
out_vector[len(indices):] = self.cbow_vocab.mask_index
return out_vector
请注意,如果上下文中的标记数量小于最大长度,则其余条目将被填入零。但在实践中,这可以称为用零填充。
CBOW 分类器
示例 5-9 中显示的 CBOW 分类器有三个基本步骤。首先,将表示上下文单词的索引与嵌入层一起使用,为上下文中的每个单词创建向量。其次,目标是以某种方式组合这些向量,使其能够捕获整个上下文。在这个例子中,我们对向量求和。然而,其他选项包括取最大值、平均值,甚至在顶部使用多层感知器(MLP)。第三,上下文向量与线性层一起用来计算预测向量。这个预测向量是整个词汇表的概率分布。预测向量中最大(最可能)的值表示目标词的可能预测——上下文中缺少的中心词。
这里使用的嵌入层主要由两个数字参数化:嵌入的数量(词汇表的大小)和嵌入的大小(嵌入维度)。示例 5-9 中的代码片段中使用了第三个参数:padding_idx。对于像我们这样数据点长度可能不相同的情况,这个参数被用作嵌入层的标记值。该层强制与该索引对应的向量及其梯度都为 0。
示例 5-9:CBOW 分类器模型
class CBOWClassifier(nn.Module):
def __init__(self, vocabulary_size, embedding_size, padding_idx=0):
"""
Args:
vocabulary_size (int): number of vocabulary items, controls the
number of embeddings and prediction vector size
embedding_size (int): size of the embeddings
padding_idx (int): default 0; Embedding will not use this index
"""
super(CBOWClassifier, self).__init__()
self.embedding = nn.Embedding(num_embeddings=vocabulary_size,
embedding_dim=embedding_size,
padding_idx=padding_idx)
self.fc1 = nn.Linear(in_features=embedding_size,
out_features=vocabulary_size)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
x_embedded_sum = self.embedding(x_in).sum(dim=1)
y_out = self.fc1(x_embedded_sum)
if apply_softmax:
y_out = F.softmax(y_out, dim=1)
return y_out
训练例程
在这个例子中,训练程序遵循我们在整本书中使用的标准。首先,初始化数据集、向量化器、模型、损失函数和优化器。然后,对数据集的训练和验证部分进行一定次数的迭代,优化训练部分的损失最小化,测量验证部分的进度。关于训练程序的更多细节,我们建议您参考“示例:餐厅评论的情绪分类”,在这里我们将详细介绍。示例 5-10 展示了我们用于训练的参数。
示例 5-10:CBOW 训练脚本的参数
Input[0]
args = Namespace(
# Data and Path information
cbow_csv="data/books/frankenstein_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch5/cbow",
# Model hyper parameters
embedding_size=300,
# Training hyper parameters
seed=1337,
num_epochs=100,
learning_rate=0.001,
batch_size=128,
early_stopping_criteria=5,
# Runtime options omitted for space
)
模型评估和预测
本例中的评估是为测试集中的每个目标和上下文对从提供的单词上下文预测目标单词。正确分类的单词意味着模型正在学习从上下文预测单词。在本例中,该模型在测试集上达到了 15% 的目标词分类准确率。首先,本例中 CBOW 的构建旨在说明如何构建通用嵌入。因此,原始实现的许多特性被忽略了,因为它们增加了不必要的复杂性,但对于优化性能却是必要的。第二,我们使用的数据集是微不足道的——一本大约 7 万字的书不足以在从零开始训练时识别出许多规律。相比之下,最先进嵌入技术通常是在文本为 tb 的数据集上进行训练。
在这个例子中,我们展示了如何使用 PyTorch nn.Embedding层通过设置一个名为CBOWClassification的人工监督任务来从头开始训练嵌入。 在下一个示例中,我们将研究如何在一个语料库中进行预训练嵌入,如何使用它并对其进行微调以进行其他任务。 在机器学习中,使用在一个任务上训练的模型作为另一个任务的初始化器称为迁移学习(transfer learning)。
示例:使用预训练嵌入用于文档分类的迁移学习
前面的示例使用一个嵌入层(embedding layer)做简单分类,这个例子构建在三个方面:首先,通过加载预训练的词嵌入,然后微调这些预训练嵌入整个新闻文章分类,最后用卷积神经网络(CNN)来捕获单词之间的空间关系。
在这个例子中,我们使用 AG News 数据集。为了对 AG News 中的单词序列进行建模,我们引入了词汇表类的一个变体SequenceVocabulary,以捆绑一些对建模序列至关重要的标记。向量化器演示了如何使用这个类。
在描述了数据集以及向量化的小批量是如何构建的之后,我们将逐步将预先训练好的单词向量加载到一个嵌入层中,并演示如何根据我们的设置对它们进行定制。然后,将预训练的嵌入层与“用 CNN 对姓氏进行分类的例子”中使用的 CNN 结合起来。为了将模型的复杂性扩大到更实际的结构,我们还确定了使用丢弃作为正则化技术的地方。给出了模型描述,然后讨论了训练过程。您可能不会感到惊讶的是,与第 4 章和本章中的前两个示例相比,训练例程几乎没有什么变化。最后,通过在测试集上对模型进行评价并对结果进行讨论,得出了算例。
AG 新闻数据集
AG news 数据集是由学者们在 2005 年为实验数据挖掘和信息提取方法而收集的 100 多万篇新闻文章的集合。这个例子的目的是说明预先训练的词嵌入在文本分类中的有效性。在本例中,我们使用精简版的 120,000 篇新闻文章,这些文章平均分为四类:体育、科学/技术、世界和商业。除了精简数据集之外,我们还将文章标题作为我们的观察重点,并创建多类分类任务来预测给定标题的类别。
和以前一样,我们通过删除标点符号、在标点符号周围添加空格(如逗号、撇号和句点)来预处理文本,并将文本转换为小写。另外,我们将数据集分解为训练、验证和测试集,首先通过类标签聚合数据点,然后将每个数据点分配给三个分割中的一个。通过这种方式,保证了跨分支的类分布是相同的。
AG news 数据集的__getitem__,第 5-11 所示的例子,是一个相当基本的公式你现在应该熟悉:检索的字符串表示模型的输入数据集从一个特定的行,Vectorizer向量化,并搭配整数代表新闻类别(类标签)。
示例 5-11:AG 新闻数据集的__getitem__方法
class NewsDataset(Dataset):
@classmethod
def load_dataset_and_make_vectorizer(cls, news_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
news_df = pd.read_csv(news_csv)
train_news_df = news_df[news_df.split=='train']
return cls(news_df, NewsVectorizer.from_dataframe(train_news_df))
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dict holding the data point's features (x_data) and label (y_target)
"""
row = self._target_df.iloc[index]
title_vector = \
self._vectorizer.vectorize(row.title, self._max_seq_length)
category_index = \
self._vectorizer.category_vocab.lookup_token(row.category)
return {'x_data': title_vector,
'y_target': category_index}
Vocabulary,Vectorizer和DataLoader
在这个例子中,我们引入了SequenceVocabulary,它是标准Vocabulary类的子类,它捆绑了用于序列数据的四个特殊标记:UNK标记,MASK标记,BEGIN-SEQUENCE标记和END-SEQUENCE标记。 我们在第 6 章中更详细地描述了这些标记,但简而言之,它们有三个不同的用途。 我们在第 4 章中看到的UNK标记(Unknown 的缩写)允许模型学习稀有单词的表示,以便它可以容纳在测试时从未见过的单词。 当我们有可变长度的序列时,MASK标记充当嵌入层和损失计算的标记。 最后,BEGIN-SEQUENCE和END-SEQUENCE标记给出了关于序列边界的神经网络提示。 图 5-3 显示了在更广泛的向量化管道中使用这些特殊标记的结果。
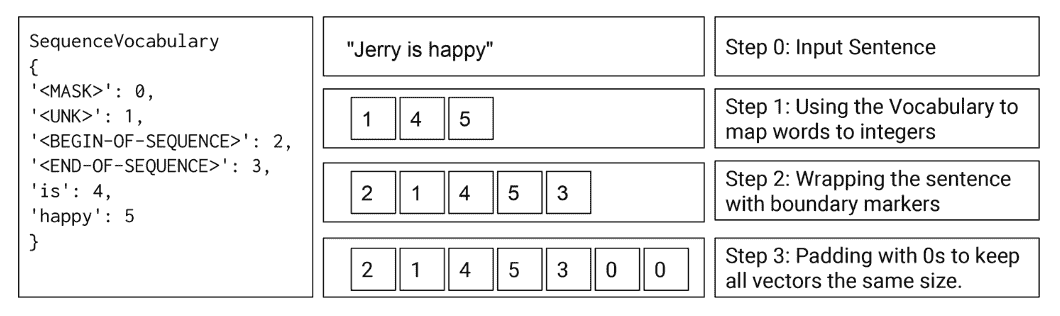
图 5-3. 向量化管道的一个简单示例从基本序列序列开始。Sequencevocabulary有四个特殊标记描述在文本。首先,它用于将单词映射到整数序列。因为单词Jerry不在序列表中,所以它被映射到unk整数。接下来,标记句子边界的特殊标记放在前面并附加到整数中。最后,整数用 0 填充到特定的长度,这允许数据集中的每个向量都是相同的长度。
文本到向量化的小批量管道中的第二个组件是Vectorizer,它实例化并封装了SequenceVocabulary的使用。 在这个例子中,Vectorizer遵循我们在第 3-5 节中演示的模式,通过对特定频率进行计数和阈值处理来限制词汇表中允许的总词集。 此操作的核心目的是通过消除噪声,低频字并限制内存模型的内存使用来提高模型的信号质量。
实例化后,Vectorizer的vectorize()方法将新闻标题作为输入,并返回与数据集中最长标题一样长的向量。重要的是,它有两个关键行为。第一个是它在本地存储最大序列长度。通常,数据集跟踪最大序列长度,并且在推断时,测试序列的长度被视为向量的长度。但是,因为我们有 CNN 模型,所以即使在推理时也要保持静态大小。示例 5-11 中的代码片段中显示的第二个键行为是它输出一个零填充的整数向量,它表示序列中的单词。此外,这个整数向量具有前缀为开头的BEGIN-SEQUENCE标记的整数,以及附加到向量末尾的END-SEQUENCE标记的整数。从分类器的角度来看,这些特殊标记提供了序列边界的证据,使其能够对边界附近的单词作出反应,而不是对靠近中心的单词作出反应。
示例 5-12:为 AG 新闻数据集实现向量化器
class NewsVectorizer(object):
def vectorize(self, title, vector_length=-1):
"""
Args:
title (str): the string of words separated by a space
vector_length (int): forces the length of index vector
Returns:
the vectorized title (numpy.array)
"""
indices = [self.title_vocab.begin_seq_index]
indices.extend(self.title_vocab.lookup_token(token)
for token in title.split(" "))
indices.append(self.title_vocab.end_seq_index)
if vector_length < 0:
vector_length = len(indices)
out_vector = np.zeros(vector_length, dtype=np.int64)
out_vector[:len(indices)] = indices
out_vector[len(indices):] = self.title_vocab.mask_index
return out_vector
@classmethod
def from_dataframe(cls, news_df, cutoff=25):
"""Instantiate the vectorizer from the dataset dataframe
Args:
news_df (pandas.DataFrame): the target dataset
cutoff (int): frequency threshold for including in Vocabulary
Returns:
an instance of the NewsVectorizer
"""
category_vocab = Vocabulary()
for category in sorted(set(news_df.category)):
category_vocab.add_token(category)
word_counts = Counter()
for title in news_df.title:
for token in title.split(" "):
if token not in string.punctuation:
word_counts[token] += 1
title_vocab = SequenceVocabulary()
for word, word_count in word_counts.items():
if word_count >= cutoff:
title_vocab.add_token(word)
return cls(title_vocab, category_vocab)
新闻分类器
在本章的前面,我们看到了如何从磁盘加载预训练嵌入,并使用 Spotify 的 Annoy 库中的近似最近邻数据结构有效地使用它们。 在该示例中,我们将向量相互比较以发现有趣的语言学见解。 但是,预训练的单词向量具有更有效的用途:我们可以使用它们来初始化嵌入层的嵌入矩阵。
使用单词嵌入(word embedding)作为初始嵌入矩阵的过程首先从磁盘加载嵌入,然后为数据中实际存在的单词选择正确的嵌入子集,然后最后设置嵌入层的权重矩阵 作为加载的子集。 在例 5-13 中演示了选择子集的第一步和第二步。 通常出现的一个问题是数据集中存在的单词,但不包含在预训练的 GloVe 嵌入中。 处理此问题的一种常用方法是使用 PyTorch 库中的初始化方法,例如 Xavier Uniform 方法,如例 5-13 所示(Glorot 和 Bengio,2010)。
示例 5-13:基于词汇表选择词嵌入的子集
def load_glove_from_file(glove_filepath):
"""Load the GloVe embeddings
Args:
glove_filepath (str): path to the glove embeddings file
Returns:
word_to_index (dict), embeddings (numpy.ndarray)
"""
word_to_index = {}
embeddings = []
with open(glove_filepath, "r") as fp:
for index, line in enumerate(fp):
line = line.split(" ") # each line: word num1 num2 ...
word_to_index[line[0]] = index # word = line[0]
embedding_i = np.array([float(val) for val in line[1:]])
embeddings.append(embedding_i)
return word_to_index, np.stack(embeddings)
def make_embedding_matrix(glove_filepath, words):
"""Create embedding matrix for a specific set of words.
Args:
glove_filepath (str): file path to the glove embeddings
words (list): list of words in the dataset
Returns:
final_embeddings (numpy.ndarray): embedding matrix
"""
word_to_idx, glove_embeddings = load_glove_from_file(glove_filepath)
embedding_size = glove_embeddings.shape[1]
final_embeddings = np.zeros((len(words), embedding_size))
for i, word in enumerate(words):
if word in word_to_idx:
final_embeddings[i, :] = glove_embeddings[word_to_idx[word]]
else:
embedding_i = torch.ones(1, embedding_size)
torch.nn.init.xavier_uniform_(embedding_i)
final_embeddings[i, :] = embedding_i
return final_embeddings
此示例中的NewsClassifier建立在第 4-4 节中的 ConvNet 分类器上,其中我们使用 CNN 对字符的单热嵌入对姓氏进行分类。 具体来说,我们使用嵌入层,它将输入标记索引映射到向量表示。 我们通过替换嵌入层的权重矩阵来使用预训练嵌入子集,如例 5-14 所示。 然后在前向方法中使用嵌入以从索引映射到向量。 除了嵌入层,一切都与第 4-4 节中的示例完全相同。
示例 5-14:实现新闻分类器
class NewsClassifier(nn.Module):
def __init__(self, embedding_size, num_embeddings, num_channels,
hidden_dim, num_classes, dropout_p,
pretrained_embeddings=None, padding_idx=0):
"""
Args:
embedding_size (int): size of the embedding vectors
num_embeddings (int): number of embedding vectors
filter_width (int): width of the convolutional kernels
num_channels (int): number of convolutional kernels per layer
hidden_dim (int): the size of the hidden dimension
num_classes (int): the number of classes in classification
dropout_p (float): a dropout parameter
pretrained_embeddings (numpy.array): previously trained word embeddings
default is None. If provided,
padding_idx (int): an index representing a null position
"""
super(NewsClassifier, self).__init__()
if pretrained_embeddings is None:
self.emb = nn.Embedding(embedding_dim=embedding_size,
num_embeddings=num_embeddings,
padding_idx=padding_idx)
else:
pretrained_embeddings = torch.from_numpy(pretrained_embeddings).float()
self.emb = nn.Embedding(embedding_dim=embedding_size,
num_embeddings=num_embeddings,
padding_idx=padding_idx,
_weight=pretrained_embeddings)
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=embedding_size,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self._dropout_p = dropout_p
self.fc1 = nn.Linear(num_channels, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, dataset._max_seq_length)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, num_classes)
"""
# embed and permute so features are channels
x_embedded = self.emb(x_in).permute(0, 2, 1)
features = self.convnet(x_embedded)
# average and remove the extra dimension
remaining_size = features.size(dim=2)
features = F.avg_pool1d(features, remaining_size).squeeze(dim=2)
features = F.dropout(features, p=self._dropout_p)
# final linear layer to produce classification outputs
intermediate_vector = F.relu(F.dropout(self.fc1(features),
p=self._dropout_p))
prediction_vector = self.fc2(intermediate_vector)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
训练例程
训练例程包括以下操作序列:实例化数据集; 实例化模型; 实例化损失函数; 实例化优化器; 迭代数据集的训练分区并更新模型参数,迭代数据集的验证分区并测量性能; 然后重复数据集迭代一定次数。 此时,您应该非常熟悉这个序列。 示例 5-15 中显示了此示例的超参数和其他训练参数。
示例 5-15:使用与训练嵌入的 CNN 新闻分类器的参数
args = Namespace(
# Data and path hyper parameters
news_csv="data/ag_news/news_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch5/document_classification",
# Model hyper parameters
glove_filepath='data/glove/glove.6B.100d.txt',
use_glove=False,
embedding_size=100,
hidden_dim=100,
num_channels=100,
# Training hyper parameter
seed=1337,
learning_rate=0.001,
dropout_p=0.1,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
# ... runtime options not shown for space
)
模型评估和分类
在这个例子中,任务是将新闻标题分类到它们各自的类别。正如您在前面的示例中看到的,有两种方法可以理解模型执行任务的好坏:使用测试数据集的定量评估,以及亲自检查分类结果的定性评估。
在测试集上评估
虽然这是你第一次看到的任务分类新闻头条,定量评价例程应该出现一模一样的每一评估程序:设置模型在求值模式关掉丢弃和反向传播(使用classifier.eval()),然后遍历测试集以同样的方式作为训练集和验证集。在典型的环境中,您应该尝试不同的训练选项,当您满意时,您应该执行模型评估。我们会把这个留到练习结束。在这个测试集中你能得到的最终准确度是多少?请记住,在整个实验过程中,您只能使用测试集一次。
预测新的新闻头条的类别
训练分类器的目标是将其部署到生产环境中,以便能够对不可见的新闻标题执行推理或预测。要预测尚未处理和数据集中的新闻标题的类别,有几个步骤。第一种是对文本进行预处理,其方式类似于对训练中的数据进行预处理。对于推理,我们对输入使用与训练中相同的预处理函数。该预处理字符串使用训练期间使用的向量化器向量化,并转换为 PyTorch 张量。接下来,对它应用分类器。计算预测向量的最大值以查找类别的名称。示例 5-16 给出了代码。
示例 5-16:使用训练模型做出预测
def predict_category(title, classifier, vectorizer, max_length):
"""Predict a News category for a new title
Args:
title (str): a raw title string
classifier (NewsClassifier): an instance of the trained classifier
vectorizer (NewsVectorizer): the corresponding vectorizer
max_length (int): the max sequence length
Note: CNNs are sensitive to the input data tensor size.
This ensures to keep it the same size as the training data
"""
title = preprocess_text(title)
vectorized_title = \
torch.tensor(vectorizer.vectorize(title, vector_length=max_length))
result = classifier(vectorized_title.unsqueeze(0), apply_softmax=True)
probability_values, indices = result.max(dim=1)
predicted_category = vectorizer.category_vocab.lookup_index(indices.item())
return {'category': predicted_category,
'probability': probability_values.item()}
总结
在本章中,我们研究了单词嵌入,这是一种在空间中将单词(如单词)表示为固定维度向量的方式,使得向量之间的距离编码各种语言属性。 重要的是要记住,本章介绍的技术适用于任何离散单元,如句子,段落,文档,数据库记录等。 这使得嵌入技术对于深度学习是必不可少的,特别是在 NLP 中。 我们展示了如何以黑盒方式使用预训练嵌入。 我们简要讨论了直接从数据中学习这些嵌入的几种方法,包括连续词袋(CBOW)方法。 我们展示了如何在语言建模的背景下训练 CBOW 模型。 最后,我们通过一个在文档分类等任务中使用预训练嵌入和微调嵌入的示例。
不幸的是,本章由于缺乏空间而遗漏了许多重要的主题,例如消除词嵌入,建模上下文和一词多义。语言数据是世界的反映。社会偏见可以通过有偏见的训练语料库编码成模型。在一项研究中,最接近代词“她”的词是家庭主妇,护士,接待员,图书管理员,理发师等,而最接近“他”的词则是外科医生,保护者,哲学家,建筑师,金融家等等。 。对这种有偏见的嵌入进行过训练的模型可以继续做出可能产生不公平结果的决策。不再使用单词嵌入仍然是一个新生的领域,我们建议您阅读 Bolukbasi 等人.(2016 年)和最近的论文引用了这一点。我们使用的嵌入词不依赖于上下文。例如,根据上下文,单词play可能有两个不同的含义,但这里讨论的所有嵌入(embedding)方法都会破坏这两个含义。最近的作品如 Peters(2018)探索了以上下文为条件提供嵌入的方法。